一般来说,监控 Substrate 框架开发的区块链节点,可以使用官方推荐的 Prometheus + Grafana 技术栈。在节点数量比较多的情况下,这套方案的优势比较容易体现出来,我给公司的官方节点也是这么配的。不过近期 Darwinia 主网上线,有不少同事想要跑自己的验证人(validator)节点。对于他们来说:
- 搭建一套 Prometheus 还要自己调面板和规则,成本实在太高;
- 只用 PM2、Supervisord、Systemd 之类的守护进程通常只能保证进程没挂,但节点是否正常出块是未知的(例如断网、0 Peer 的情况,节点进程还在,其实已经掉线了)。
为了解决以上这两个问题,我搞了一套非常简易的、基于日志的监控预警方法。
🚀 KUBE-VALI 是基于 Kubernetes 集群大规模部署的节点,稳定可靠,求大佬投票。
基本思路
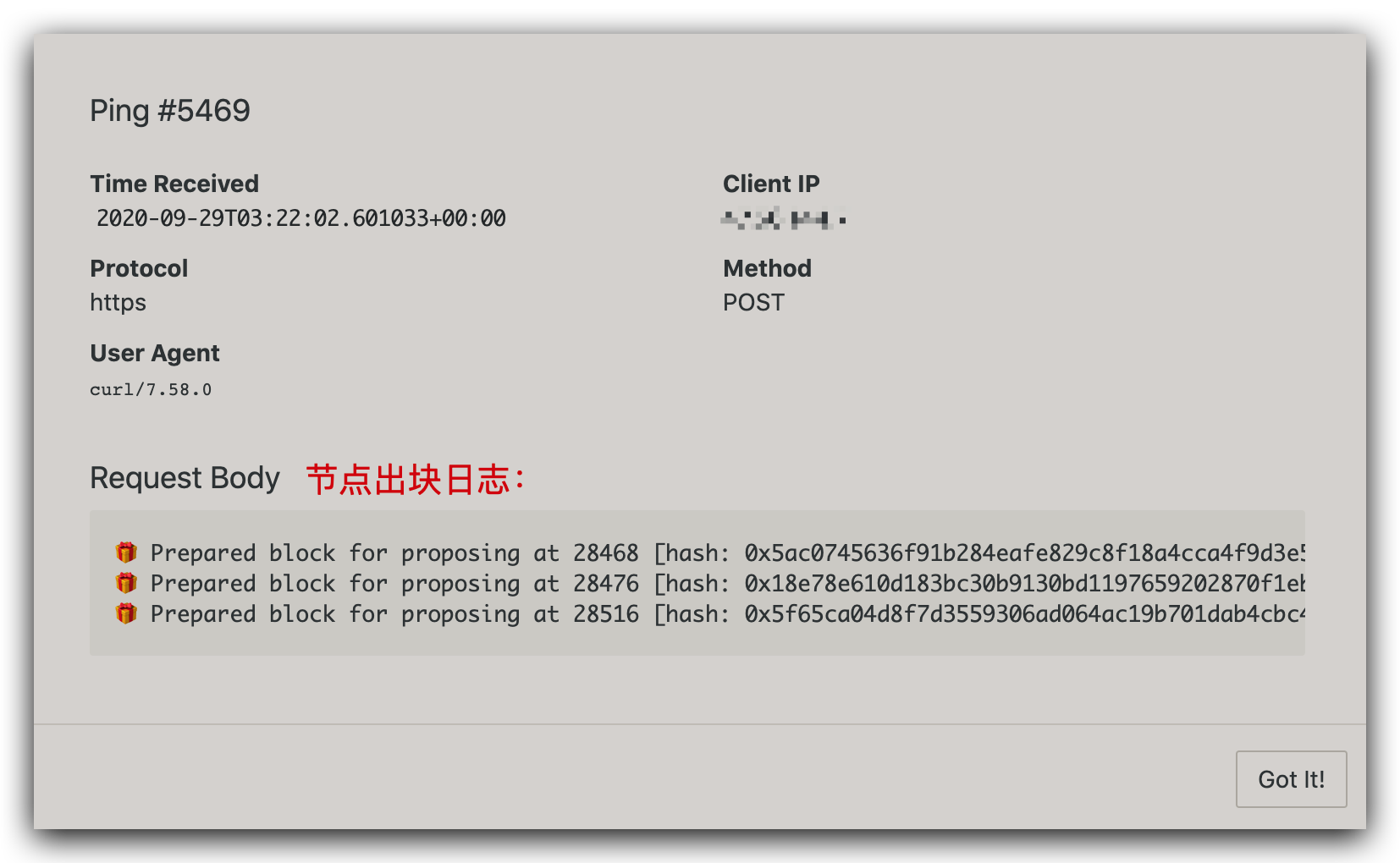
基于 Darwinia 验证人产块,会有类似 🎁 Prepared block for proposing at ... 的日志输出,只要有个脚本不断检查节点日志,如果一段时间内没有类似的输出,说明节点可能已经出了问题,发送通知或重启节点均可。
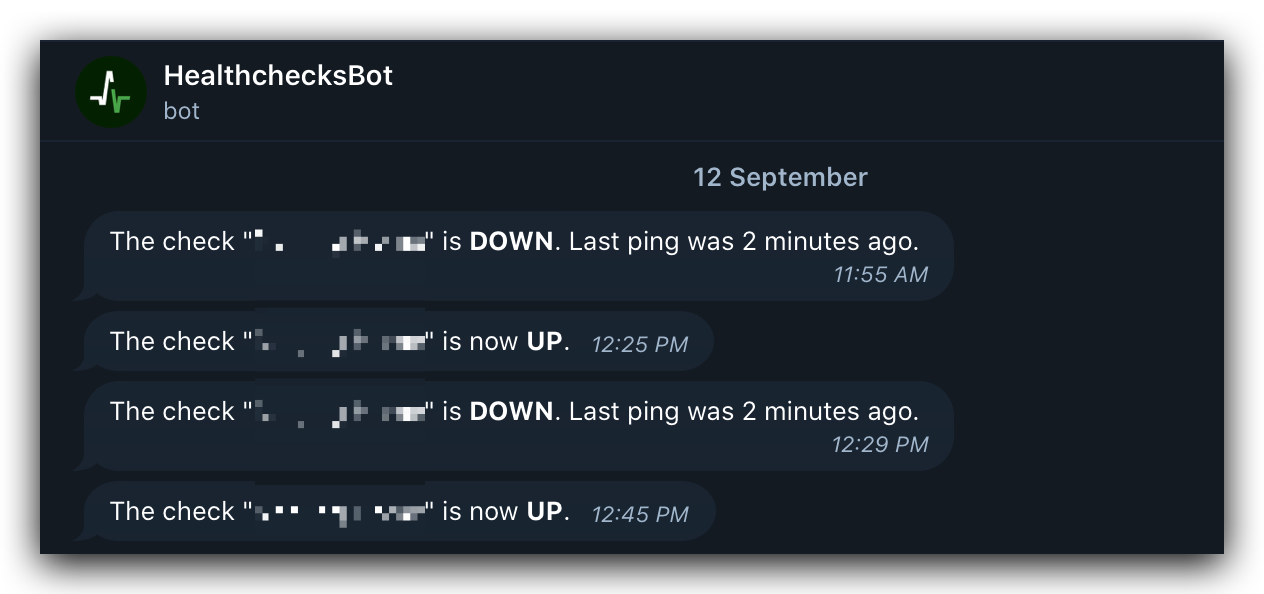
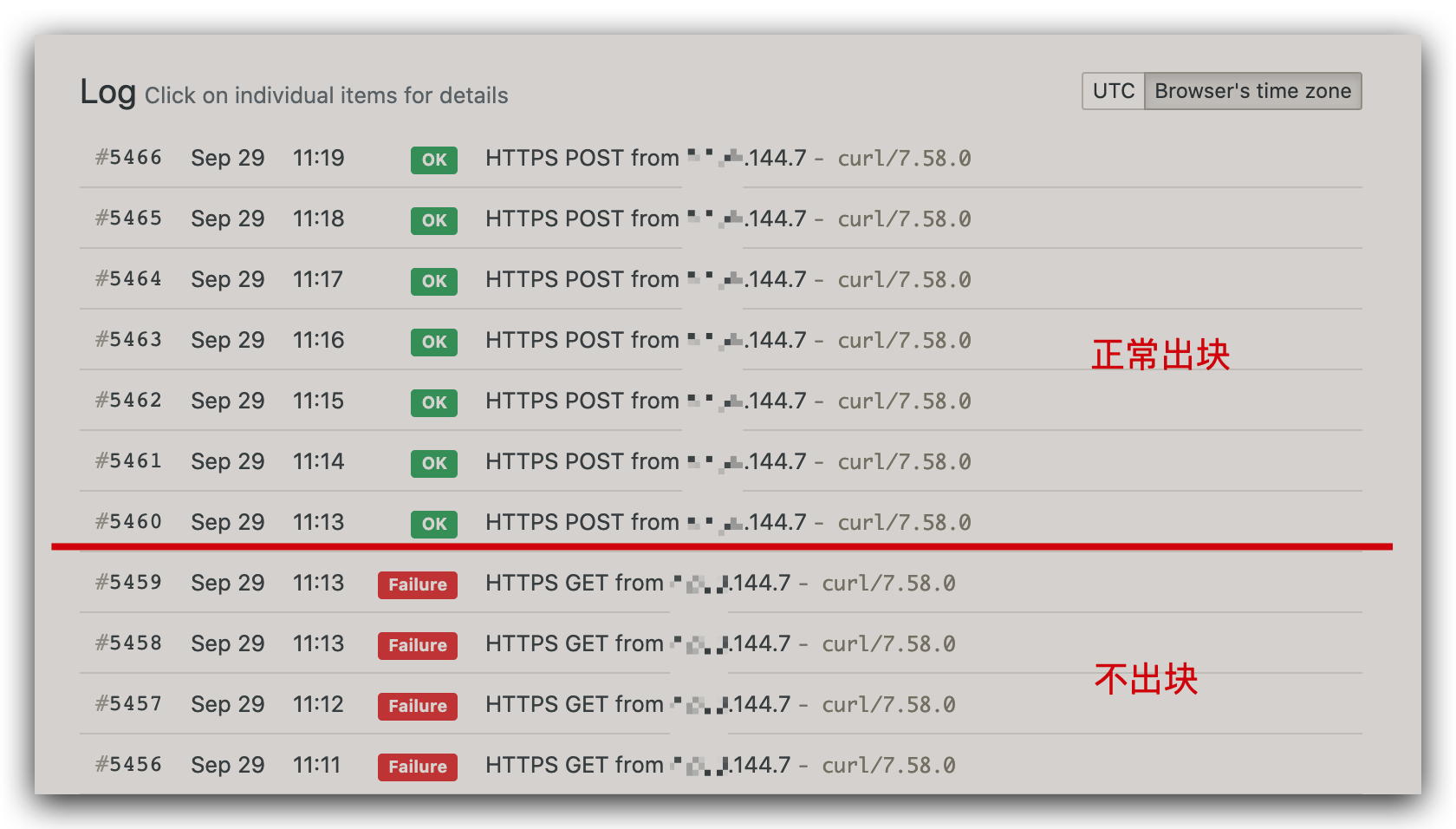
最终效果
具体步骤
1) 实现检查日志
首先登录你的验证人节点,创建一个 Watchlog 脚本,例如 /usr/bin/darwinia-watchlog.sh:
#!/usr/bin/env bash
RETRIVE_LOG_COMMAND="journalctl -u darwinia-node.service -o cat --since -30m"
# RETRIVE_LOG_COMMAND="docker logs darwinia-node --since 30m"
echo "[INFO] Checking Darwinia logs..."
DARWINIA_LOGS="$($RETRIVE_LOG_COMMAND | grep 'Prepared block')"
if [ $? -eq 0 ]; then
echo "[INFO] New blocks detected."
else
echo "[WARN] No blocks deteched!"
fi
RETRIVE_LOG_COMMAND是用来获取近期节点日志的命令。我列出了两个例子,前者适用于 Systemd 启动的节点,后者适用于 Docker 启动的节点,你可以任意修改它。'Prepared block'是在日志里查找的关键词,你也可以修改为'Imported'之类的值。
随后运行该脚本,会发现有 [INFO] New blocks detected. 或是 [WARN] No blocks deteched! 的输出,说明它已经能够正常检测节点日志了。
2) 持续检查节点日志
为了能够 持续 检查节点日志,我们使用 Cron job 每分钟 调用一次该脚本就可以了。执行以下脚本新增一个每分钟执行的 Cron job:
(crontab -l ; echo "* * * * * /usr/bin/darwinia-watchlog.sh | logger -t darwinia-watchlog") 2>&1 | grep -v "no crontab" | sort | uniq | crontab -
3) 预警通知和重启
自己写通知太麻烦,不如试试 https://healthchecks.io/ 吧。Healthchecks.io 是一款 开源的 定时任务监控、通知系统。它假设你的脚本在「某一时刻」运行,正常情况下,你的脚本运行成功并给它发送一个成功消息;如果你的脚本没有运行,或是执行出错,它能够按照指定的通知渠道,给你发送一条预警通知。
注册后首先在 Integrations 里添加通知渠道,例如我添加了我的 Telegram:
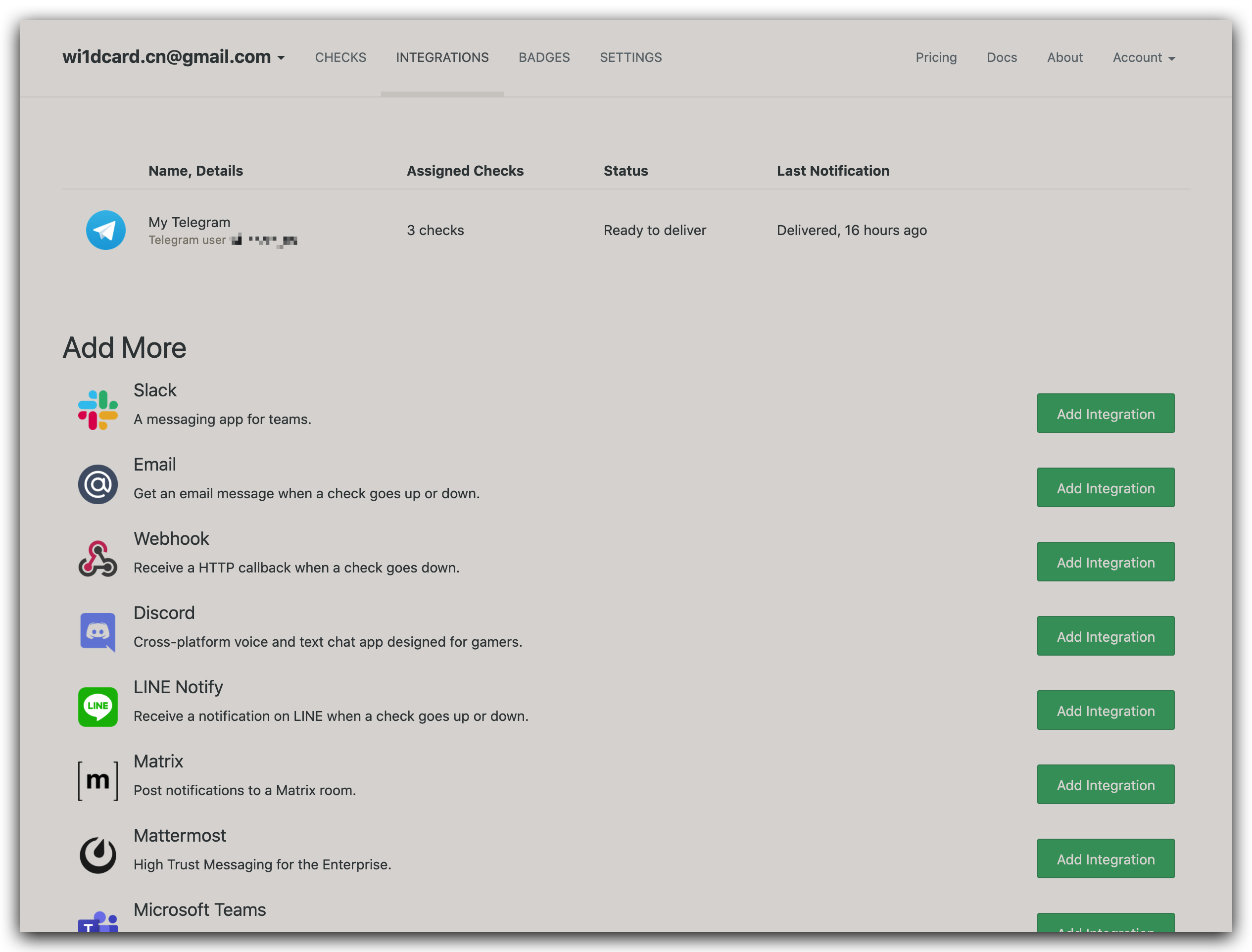
随后在 Checks 页面点击 Add Check 新增一个 Check,会跳到新创建的 Check 的信息页面:
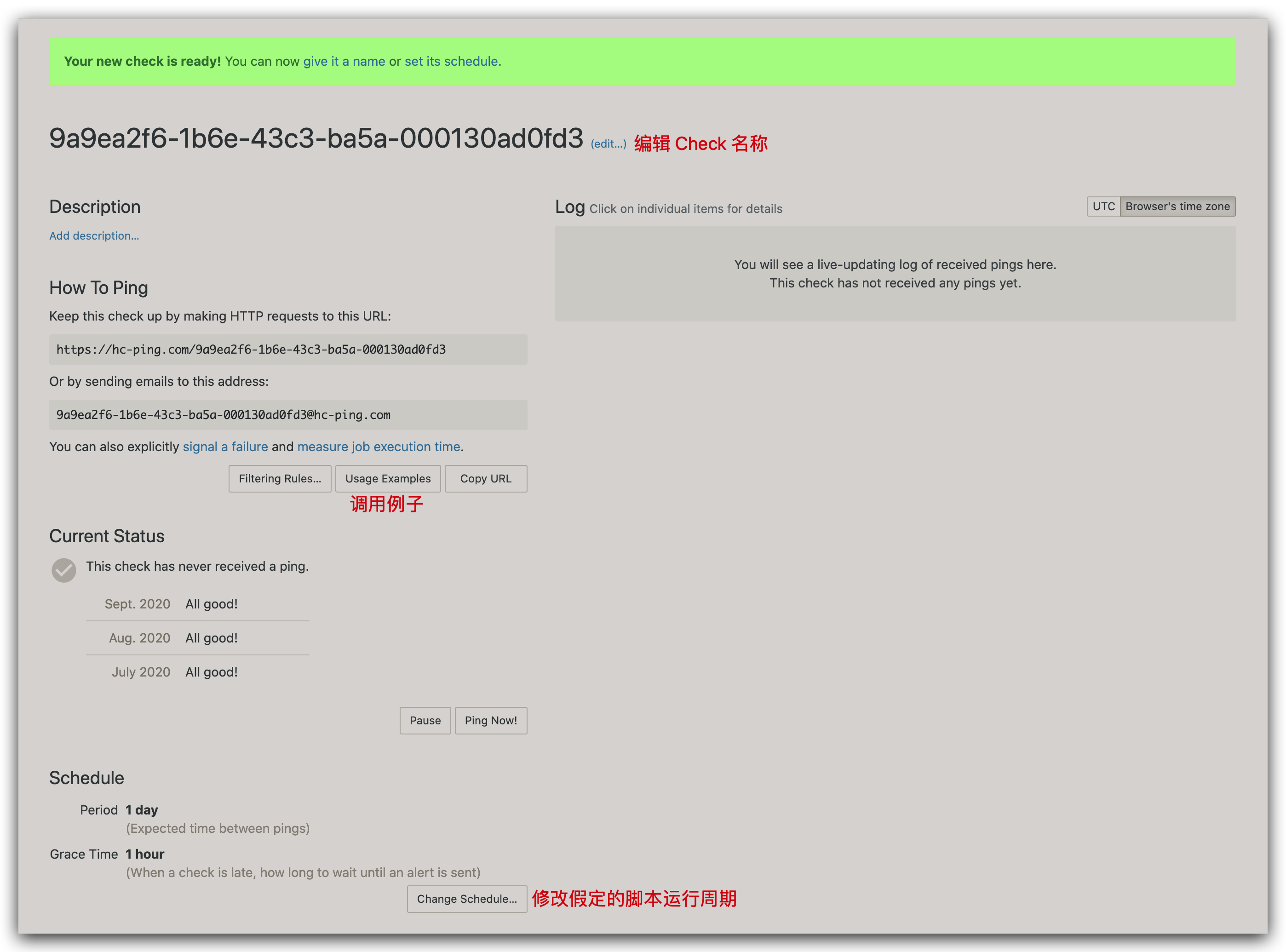
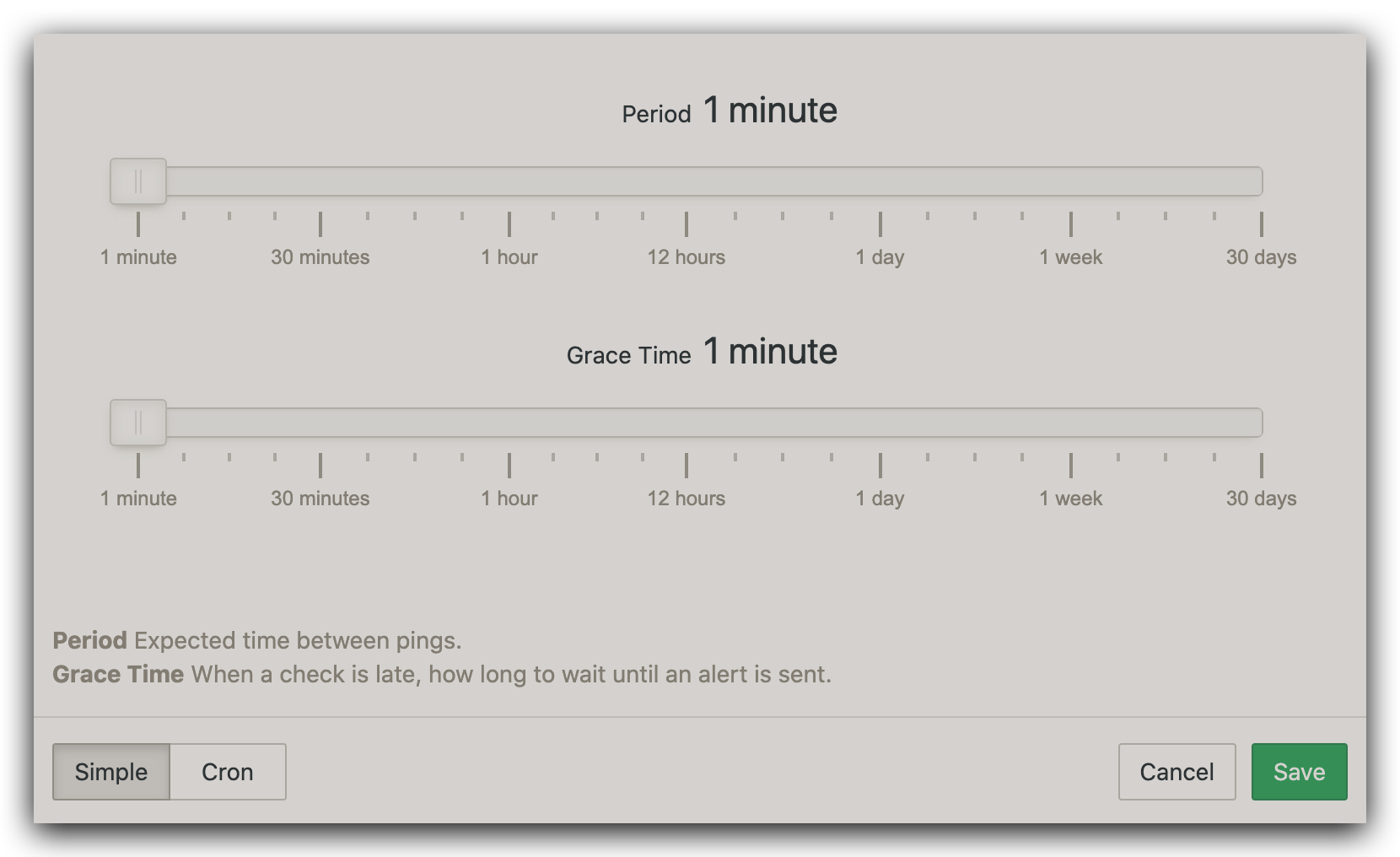
Schedule 是肯定要改的,需要跟我们脚本的实际运行计划匹配,点击 Change Schedule...,把 Period 和 Grace Time 全部调成 1 minute:
最后点击 Usage Examples...,找到 Bash 的例子,复制这行命令:
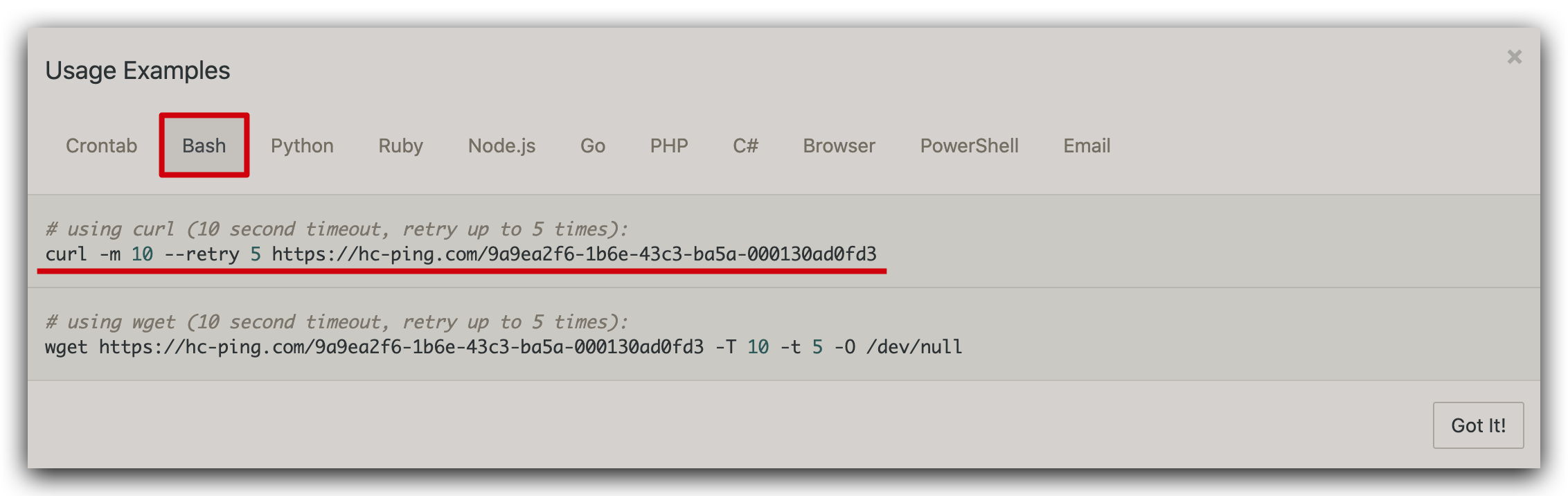
回到我们的节点机器上,修改 /usr/bin/darwinia-watchlog.sh 脚本,在 echo "[INFO] New blocks detected." 之后添加这行命令就可以了:
# ...
if [ $? -eq 0 ]; then
echo "[INFO] New blocks detected."
curl -m 10 --retry 5 https://hc-ping.com/9a9ea2f6-1b6e-43c3-ba5a-000130ad0fd3 # 在这里
# ...
这样我们的脚本在每分钟定时执行时,如果有检查到新块产生,就会输出 [INFO] New blocks detected.,并调用 healthchecks.io。如果没有检查到,就不会调用 healthchecks.io,进而 healthchecks.io 会默认执行失败,从而发起通知。
最终改进后的完整脚本
你可以直接复制以下脚本,我还做了一些其它的小优化,修改 !!! HEALTH CHECK ID !!! 即可使用。
#!/usr/bin/env bash
RETRIVE_LOG_COMMAND="journalctl -u darwinia-node.service -o cat --since -30m"
# RETRIVE_LOG_COMMAND="docker logs darwinia-node --since 30m"
HEALTHCHECK_IO_URL="https://hc-ping.com/!!! HEALTH CHECK ID !!!" # 别忘记填入 Healthchecks.io 的 URL
echo "[INFO] Checking Darwinia logs..."
DARWINIA_LOGS="$($RETRIVE_LOG_COMMAND | grep 'Prepared block')"
if [ $? -eq 0 ]; then
echo "[INFO] New blocks detected."
echo -n "[INFO] Notifying healthchecks.io... "
curl -fsS --max-time 10 --retry 3 --data-raw "$DARWINIA_LOGS" "$HEALTHCHECK_IO_URL"
else
echo "[WARN] No blocks deteched!"
echo -n "[INFO] Notifying healthchecks.io... "
curl -fsS --max-time 10 --retry 3 "$HEALTHCHECK_IO_URL/fail"
fi
你可以执行 journalctl SYSLOG_IDENTIFIER=darwinia-watchlog -f 观察脚本运行日志:
Sep 29 10:49:01 darwinia-watchlog[19493]: [INFO] Checking Darwinia logs...
Sep 29 10:49:01 darwinia-watchlog[19493]: [INFO] New blocks detected.
Sep 29 10:49:01 darwinia-watchlog[19493]: [INFO] Notifying healthchecks.io... OK
Sep 29 10:50:01 darwinia-watchlog[19503]: [INFO] Checking Darwinia logs...
Sep 29 10:50:01 darwinia-watchlog[19503]: [INFO] New blocks detected.
Sep 29 10:50:02 darwinia-watchlog[19503]: [INFO] Notifying healthchecks.io... OK
...
写在最后
- 其实这个方案是受到 GCP Log-based metrics 启发而实现的,最早我的思路是用 ELK 分析日志,但某天突然灵光一现 — 根本不用这么麻烦,直接写个脚本 + CRON 定时执行 + 随便找个外部监控就好了。
- 其实也可以不用 CRON,改用脚本死循环也可以。不过这样就增加了脚本本身的复杂度,另外还得处理常驻进程等问题。
- 另外也可以不用 healthcheck.io,直接在脚本内发通知。但同样得考虑:万一脚本也崩了怎么办?如果验证人节点彻底断网,根本发不出来通知怎么办?单台机器无法解决,再开一台机器用作监控违背了这个方案的初心,而利用外部的、被动的(即使机器挂了发不出来通知也能被监控捕捉到)监控服务是我目前能想到成本最低廉的解决方案了。